
{kind=link}
OpenAI разработала новый эталонный тест HealthBench для оценки медицинских знаний языковых моделей. В его создании приняли участие 262 врача из 60 стран, разработавших 5000 реалистичных сценариев по 26 медицинским темам на 49 языках.
Тест охватывает семь областей медицины и оценивает ИИ по пяти критериям, включая качество коммуникации, точность и понимание контекста, используя 48 000 медицински обоснованных метрик. Последние модели GPT-4.1 и o3 продемонстрировали результаты, превосходящие ответы врачей во всех пяти оценочных категориях.
Если в сентябре 2024 года врачи могли улучшать ответы старых моделей, то к апрелю 2025-го новые алгоритмы стали автономно эффективнее специалистов. Модель o3 набрала 0,60 балла против 0,32 у GPT-4o лишь полгода назад, оставив позади конкурентов вроде Grok 3 и Gemini 2.5.
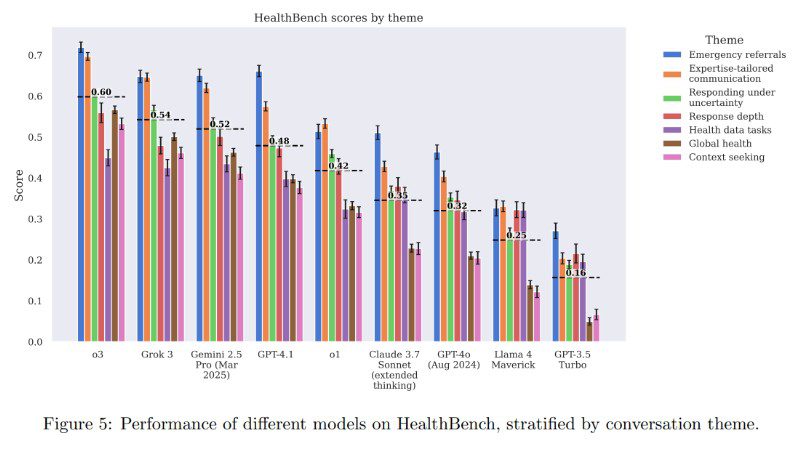
Тест оценивает только конкретный аспект коммуникации, а не реальную клиническую практику. Но GPT-4.1 сократил количество ошибок в сложных случаях, а более компактная модель GPT-4.1 nano оказалась в 25 раз экономичнее предшественников. Все материалы теста опубликованы в открытом доступе на GitHub.