
{kind=link}
OpenAI has developed a new HealthBench benchmark to assess medical knowledge of language models. It involved 262 physicians from 60 countries developing 5,000 realistic scenarios on 26 medical topics in 49 languages.
The test covers seven areas of medicine and evaluates AI on five criteria, including communication quality, accuracy and contextual understanding, using 48,000 medically valid metrics. The latest GPT-4.1 and o3 demonstrated results that outperformed physician responses in all five evaluation categories.
While in September 2024 physicians could improve on the old models’ responses, by April 2025 the new algorithms were autonomously more efficient than experts. The o3 model scored 0.60 against GPT-4o’s 0.32 only six months ago, leaving competitors like Grok 3 and Gemini 2.5 behind.
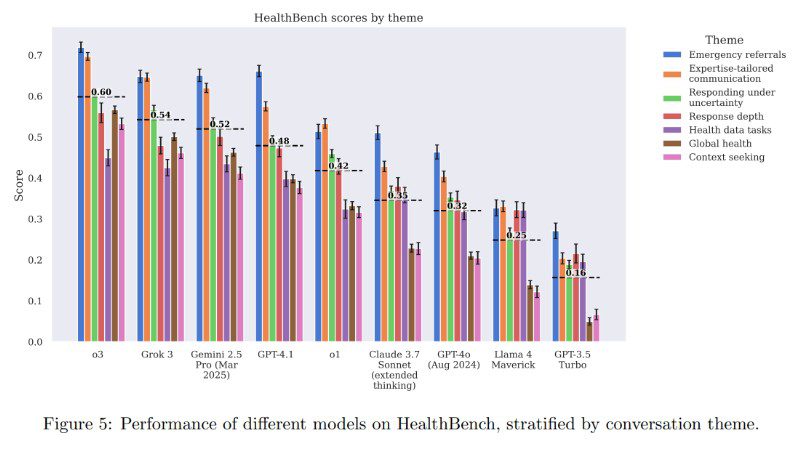
The test only evaluates a specific aspect of communication, not actual clinical practice. But the GPT-4.1 reduced errors in complex cases, and the smaller GPT-4.1 nano model was 25 times more cost-effective than its predecessors. All test materials are published in the public domain on GitHub.